March 2026 / 8 min read
How AIML Labs Engineered Sellbot AiML To Feel Like the Fastest Shopping Chatbot on the Market
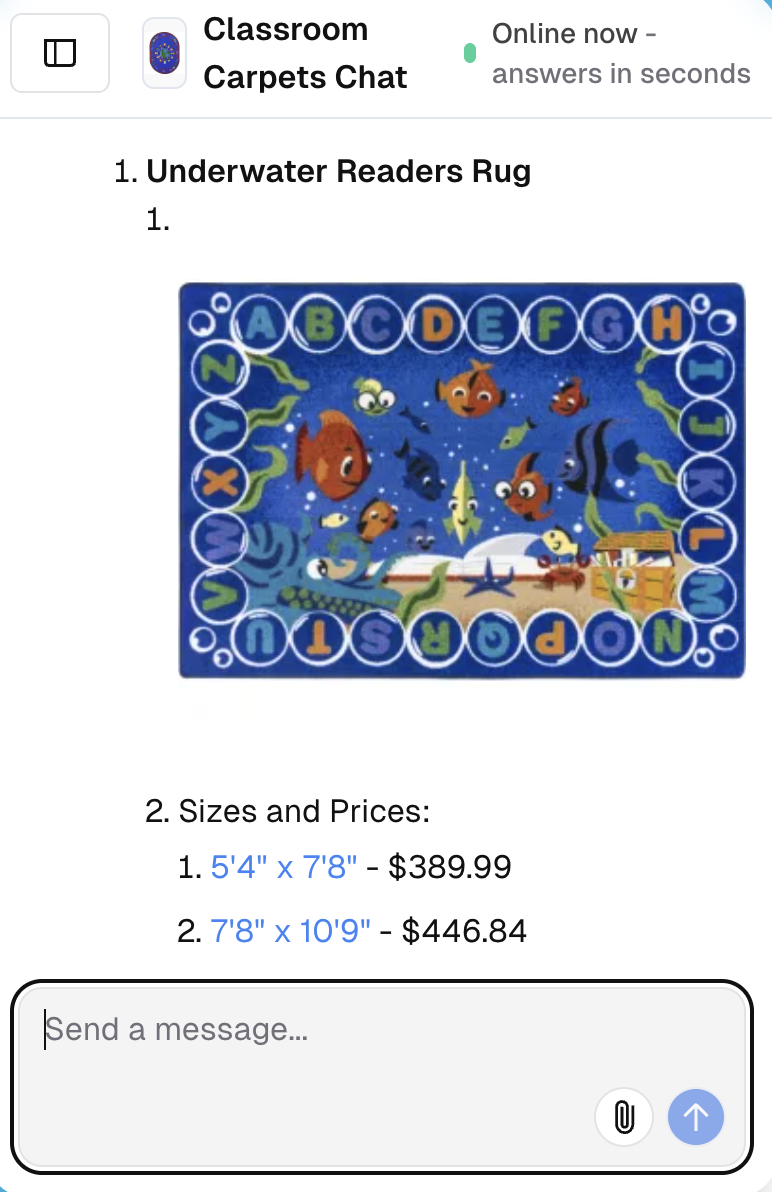
Sellbot AiML is the ecommerce product demonstration of what AiML Labs cares about most: faster answers, tighter retrieval, and a first response that already looks like shopping instead of support.
In the demo shown on this page, the system returns a product-rich answer in 2.733 seconds. That is the result of engineering choices across query shaping, product ranking, and product-first UI rendering, not just model speed in isolation.
Measured demo response
2.733s
The first product-rich answer shown in the Sellbot AiML demo flow.
Comparison benchmark
6s
A useful reminder that acceptable latency is still too slow for shopping intent.
Attention won back
3.267s
Enough time to show the shopper proof before they reconsider the tab.
Less waiting
54.4%
The kind of gap shoppers feel immediately even if they never name it.
Make the shopper feel helped before the intent cools off.
AIML Labs did not approach Sellbot like a generic chat assistant. The benchmark was stricter: if a shopper asks for something concrete, the chat must return proof fast enough to keep the session alive.
That means the latency budget is not just an infrastructure number. It is a product number. Every second saved gives the UI more room to show confidence, fit, and momentum before the customer starts comparing elsewhere.
Response-time view
Faster only matters if the answer already looks useful.
Sellbot AiML demo response
2.733s
Comparison benchmark
6.000s
Typical window to make value obvious
10.000s
Time regained
3.267s
Enough to turn uncertainty into visible merchandising.
Relative improvement
54.4%
Less waiting than the comparison benchmark.
Four choices shaped the whole product.
The engineering story is not a single trick. It is a set of constraints that make fast, high-confidence shopping responses possible at the same time.
Product card first, explanation second
AIML Labs optimized the first payload around what closes trust fastest: an actual product, a visible image, price context, and why it matched the prompt.
Tight retrieval instead of broad search
Sellbot narrows the catalog aggressively before generation. That keeps the model from wandering and keeps token volume, ranking cost, and response time under control.
Ranking for shopper intent, not generic relevance
A request like 'red backpack with laptop sleeve' should not return a pretty paragraph. It should rank the right product attributes, then render the answer like merchandising.
Latency discipline across the whole stack
Fast chat is not one optimization. It is a chain of small decisions across prompt shaping, retrieval, response assembly, image delivery, and frontend rendering.
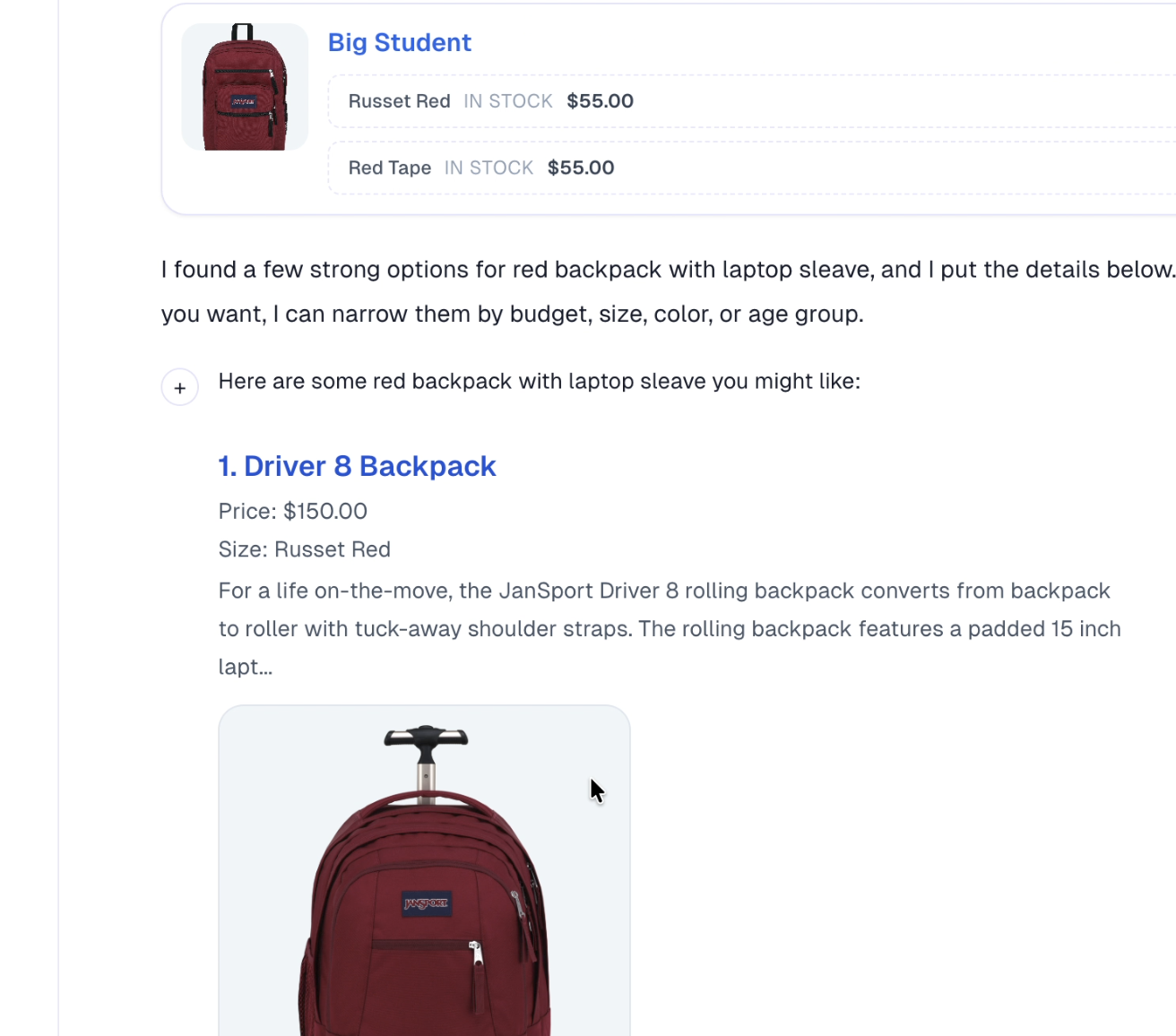
The frontend is part of the latency story.
AIML Labs treated the rendered answer as part of the model outcome. If the system retrieves the right product but forces the shopper to read through generic prose first, the product still feels slow.
That is why Sellbot pushes visible product cards, images, and concise justification directly into the conversation. The user does not need to infer that the bot understood. They can see it in the first frame.
The system is fast because the path is disciplined.
The engineering pattern is simple to describe and hard to execute well: compress intent, retrieve narrowly, rank decisively, then render the answer like a storefront instead of a help desk.
Step 01
Interpret the shopper request
Sellbot maps plain-language questions into a compact shopping intent: product type, must-have attributes, optional preferences, and likely filters.
Step 02
Query a narrowed product set
Instead of searching the whole catalog with an open-ended prompt, the system cuts down the search space first so ranking can move quickly and with less noise.
Step 03
Rank products for confidence
AIML Labs prioritizes exact fit, obvious substitutes, and clean merchandising signals so the chat can show strong options immediately instead of hedging.
Step 04
Render visual answers inside chat
The frontend turns the result into a product-first response with imagery, pricing, and concise rationale. The proof is visible in the first glance, not buried below text.
Standard shopping chat vs. the Sellbot AiML approach
The difference is not just raw model speed. It is what the system chooses to do with the first few seconds of the shopper session.
AIML Labs engineered Sellbot to win the first impression.
Shoppers do not care which optimization made the system faster. They care that the chatbot understood the request and showed the right product before they lost patience.
That is why the Sellbot AiML story matters inside the broader AiML Labs brand. It shows the company can translate AI claims into measured, visible product behavior.
The core lesson is simple: if you want a shopping chatbot to feel like the fastest in the market, you have to engineer the answer, the retrieval path, and the presentation layer as one system.
Questions leaders ask after seeing the demo
Why focus so much on the first answer?
Because the first answer decides whether the shopper treats the chatbot like a sales assistant or abandons it as another slow support layer.
Is 2.733 seconds the whole story?
No. It matters because that response is already visual and commerce-ready. Fast text alone is less useful than a slightly richer answer that still lands inside the shopper's decision window.
What makes this an AIML Labs story instead of just a Sellbot feature page?
The point of the post is the engineering approach: constrain the problem, rank aggressively, and make the first rendered answer carry merchandising value instead of filler prose.
Explore how Sellbot AiML turns product discovery into a live shopping conversation.
AIML Labs built Sellbot as a proof point for what modern commerce AI should feel like: fast, visual, and tuned to actual buying intent.
We love SchoolRugs because it is exactly the kind of Shopify store where speed and visual proof matter. Classroom rugs are specific, image-led products: shoppers want to compare themes, sizes, colors, and use cases quickly. That makes SchoolRugs a real merchandising test for Sellbot, not a synthetic demo.
Demo response
2.733s
Waiting avoided
3.267s
Product thesis
Show the shopper the right product fast enough that the conversation feels like commerce, not support.